2. Repaso de Python 3#
Este curso asume una competencia intermedia de Python. Esta lección autocontenida es sólo un refresco de memoria de las características más importantes de este lenguaje
2.1. Dynamic typing#
A diferencia de otros lenguajes, Python no requiere que el usuario declare el tipo de una variable al momento de crearla. Python interpreta el tipo de acuerdo a su valor de forma automática, como muestran los siguientes ejemplos
x = 1
type(x)
int
x = 1.
type(x)
float
x = '1'
type(x)
str
2.2. Funciones en Python#
Las funciones en Python se declaran con def. Una función puede tener argumentos de tipo posicional y argumentos con valor predefinido (tipo keyword). La salida de una función se marca con return
def foo(x, y=100):
return x + y
foo(10)
110
Si no sabemos a priori los argumentos que se usaran para invocar la función podemos usar
def foo(*args, **kwargs):
return args, kwargs
foo('asd', 21, 54, x=12, y=100)
(('asd', 21, 54), {'x': 12, 'y': 100})
*args agrupa todos los argumentos posicionales (sin nombre) mientras que **kwargs agrupa los argumentos con nombre como un diccionario
2.2.1. Función print#
En Python 3 print es una función, podemos imprimir texto formateado como
nombre = 'pablo'
apellido = 'huijse'
edad = 33
peso = 80.2
print("%s %s\t edad: %d peso: %0.4f" %(nombre, apellido, edad, peso))
print("{1} {0}\t edad: {2} peso: {3:0.4f}".format(apellido, nombre, edad, peso))
# Mi favorito: f-strings:
print(f"{nombre} {apellido}\t edad: {edad} peso: {peso:0.4f}")
pablo huijse edad: 33 peso: 80.2000
pablo huijse edad: 33 peso: 80.2000
pablo huijse edad: 33 peso: 80.2000
# Demostración del argumento sep de print
print(nombre, apellido, edad, peso, sep=' ')
pablo huijse 33 80.2
2.2.2. Decoradores#
Los decoradores son funciones que pueden modificar el funcionamiento de otra función
A continuación se muestra como se aplica un decorador llamado bar a una función llamada foo
def bar(func):
def new_func(x):
return func(x) + 10
return new_func
@bar
def foo(x):
return x +1
foo(10)
21
2.3. Estructuras de datos en Python#
2.3.1. Listas#
Son tipos de datos secuenciales que pueden ser iterados
Las listas pueden tener elementos de distinto tipo
lista_vacia = [] # Creación de una lista vacía
print(lista_vacia.append(1)) # Agregando un elemento
lista_vacia.append('hola')
print(lista_vacia) # Tiene dos elementos
print(lista_vacia.pop()) # Eliminando el primer elemento
print(lista_vacia) # Ahora tiene uno
lista_vacia[0] = 'chao' # Modificando el primer elemento
print(lista_vacia)
None
[1, 'hola']
hola
[1]
['chao']
una_lista = ['a', 'b', 'c', 1, 2, 3, 2.4, 'asd']
for elemento in una_lista:
print(elemento, end=' ')
a b c 1 2 3 2.4 asd
“Desempacando” (unpacking) una lista
primero, *medio, ultimo = una_lista
print(primero)
print(medio)
print(ultimo)
a
['b', 'c', 1, 2, 3, 2.4]
asd
primero, ultimo = ultimo, primero
print(primero, ultimo)
asd a
Imprimiendo una lista completa
print(una_lista)
print(*una_lista)
print(*una_lista, sep='-', end=' fin!')
['a', 'b', 'c', 1, 2, 3, 2.4, 'asd']
a b c 1 2 3 2.4 asd
a-b-c-1-2-3-2.4-asd fin!
Obteniendo el largo de una lista
len(una_lista)
8
Tomando slices (trozos) de una lista
print(una_lista[0])
print(una_lista[1:4])
print(una_lista[-1])
print(una_lista[::2])
print(una_lista[::-1])
a
['b', 'c', 1]
asd
['a', 'c', 2, 2.4]
['asd', 2.4, 3, 2, 1, 'c', 'b', 'a']
2.3.2. Tuplas#
Las tuplas son similares a las listas, en el sentido de que sus elementos pueden tener tipos distintos
tupla = (0, 10, 51243, 'asd')
print(tupla)
print(tupla[0])
for elemento in tupla:
print(elemento, end=' ')
(0, 10, 51243, 'asd')
0
0 10 51243 asd
Advertencia
Las tuplas (a diferencia de las listas) son inmutables, es decir no se pueden modificar
Por ejemplo la instrucción
tupla[0] = 'hola'
Returnaría una excepción de tipo TypeError
2.3.3. Rangos#
Podemos usar range para crear un iterador de números enteros
for element in range(0, 20, 2):
print(element, end=' ')
0 2 4 6 8 10 12 14 16 18
Adicionalmente podemos usar enumerate, para crear un índice entero a partir de una lista
for i in range(len(una_lista)):
print("{0}, {1}".format(i, una_lista[i]))
for i, element in enumerate(una_lista):
print("{0}, {1}".format(i, element))
0, a
1, b
2, c
3, 1
4, 2
5, 3
6, 2.4
7, asd
0, a
1, b
2, c
3, 1
4, 2
5, 3
6, 2.4
7, asd
2.3.4. Diccionario#
Es una secuencia indexada por llaves (keys)
Se puede crear un diccionario con:
d = {'nombre': 'pablo', 'apellido': 'huijse', 'edad': 33, 'peso': 80.1}
Luego si queremos leer el valor de un atributo particular utilizamos su llave
d['apellido']
'huijse'
También podemos consultar si cierta llave existe en el diccionario antes de preguntar por ella:
'edad' in d
True
Si usamos el operador list recuperamos las llaves
list(d)
['nombre', 'apellido', 'edad', 'peso']
Para iterar sobre las llaves y los valores se utiliza el método items():
for llave, valor in d.items():
print(llave, valor, sep=': ')
nombre: pablo
apellido: huijse
edad: 33
peso: 80.1
2.3.5. Sets#
Los set son una colección desordenada de objetos sin duplicados
Es posible iterar en un set, agregar/remover elementos y aplicar operaciones lógicas entre sets (intersección, union, diferencia)
Tiene complejidad O(1) de búsqueda (muy eficientes). Se deben preferir antes que las listas cuando
La colección es de gran tamaño
No hay elementos repetidos
Se realizarán múltiples búsquedas en la colección
2.3.6. Comprensiones de listas (list comprehensions)#
Representan una forma consisa de crear listas
[x for x in range(20)]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19]
texto_en_minuscula = ['Un', 'día', 'vi', 'una', 'vaca', 'vestida', 'de', 'uniforme']
texto_en_mayuscula = []
for palabra in texto_en_minuscula:
texto_en_mayuscula.append(palabra.upper())
print(texto_en_mayuscula)
print([palabra.upper() for palabra in texto_en_minuscula])
['UN', 'DÍA', 'VI', 'UNA', 'VACA', 'VESTIDA', 'DE', 'UNIFORME']
['UN', 'DÍA', 'VI', 'UNA', 'VACA', 'VESTIDA', 'DE', 'UNIFORME']
Se puede hacer una doble iteración
print([(x, y) for x in range(5) for y in range(5)])
[(0, 0), (0, 1), (0, 2), (0, 3), (0, 4), (1, 0), (1, 1), (1, 2), (1, 3), (1, 4), (2, 0), (2, 1), (2, 2), (2, 3), (2, 4), (3, 0), (3, 1), (3, 2), (3, 3), (3, 4), (4, 0), (4, 1), (4, 2), (4, 3), (4, 4)]
También se pueden aplicar condicionales en el iterador y/o en los valores
# condicional en el iterador
print([x for x in range(10) if x % 2 == 0])
[0, 2, 4, 6, 8]
# conditional en el valor
print([x**2 if x < 5 else x for x in range(10)])
[0, 1, 4, 9, 16, 5, 6, 7, 8, 9]
Puede usarse zip parar iterar sobre más de una lista
lista1 = [x for x in range(20)]
lista2 = [10]*20
lista3 = texto_en_minuscula
for elemento1, elemento2, elemento3 in zip(lista1, lista2, lista3):
print(elemento1, elemento2, elemento3, sep=', ')
0, 10, Un
1, 10, día
2, 10, vi
3, 10, una
4, 10, vaca
5, 10, vestida
6, 10, de
7, 10, uniforme
2.3.7. Iteradores#
Podemos usar iter para crear un iterador a partir de un objeto iterable (lista, tupla, rango, string, diccionario)
El iterador se evalua con next para escupir el próximo elemento, el cual sale del iterador (lazy, single-use)
Son ventajosos en términos de uso de memoría (la lista completa no se mapea en memoria)
iterador = iter(texto_en_minuscula)
print(next(iterador))
print(next(iterador))
print(list(iterador))
Un
día
['vi', 'una', 'vaca', 'vestida', 'de', 'uniforme']
Si se itera nuevamente:
print(next(iterador))
Se arroja una excepción StopIteration, ya que no quedan elementos para iterar
iterador = iter(texto_en_minuscula)
for elemento in iterador:
print(elemento)
# El iterador queda vacio luego de usarse
print(list(iterador))
Un
día
vi
una
vaca
vestida
de
uniforme
[]
Escribiendo un iterador
class Logrange:
def __init__(self, start=-6, end=6):
self.num = start
self.end = end
def __iter__(self):
return self
def __next__(self):
a = self.num
if a > self.end:
raise StopIteration
self.num += 1
return 10**a
for elemento in Logrange():
print(elemento, end=' ')
1e-06 1e-05 0.0001 0.001 0.01 0.1 1 10 100 1000 10000 100000 1000000
2.3.8. Generadores (generator function)#
Funciones que retornan un iterador
Se usa el keyword reservado yield
def gen():
for i in range(10):
yield i**2
for x in gen():
print(x, end=' ')
#print(*gen())
0 1 4 9 16 25 36 49 64 81
2.3.9. Expresión generadora (generator expression)#
Se construye como una comprensión de lista pero usando
()en vez de[]Produce una “receta” en lugar de una lista
Se consume una vez y muere
gen = (palabra for palabra in texto_en_minuscula)
print(gen)
print(next(gen))
print(next(gen))
print(next(gen))
for palabra in gen:
print(palabra, end=' ')
<generator object <genexpr> at 0x7fcf0c69e350>
Un
día
vi
una vaca vestida de uniforme
2.3.10. Otras estructuras de datos#
Sugiero revisar el módulo estándar collections que ofrece otras estructuras útiles como colas y contadores
Por ejemplo Counter permite hacer histogramas
from collections import Counter
data = [1, 1, 2, 2, 2, 3, 3, 4, 'foo']
Counter(data)
Counter({1: 2, 2: 3, 3: 2, 4: 1, 'foo': 1})
Se retorna un objeto donde la llave es el elemento único y el valor la cantidad de veces que aparece en data
2.3.11. Funciones anónimas y expresión lambda#
Son funciones de una linea con la estructura
foo = lambda argumentos: expresión
Una lambda puede tener zero o más argumentos y siempre solo una expresión
En general se usan para definir funciones anónimas, funciones que se ocupan sólo una vez en el código
lambda + map = comprensión de lista
foo = lambda x, y : x+1/y
foo(1, 2)
1.5
list(map(lambda x : x**2, range(10)))
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
list(filter(lambda x : x % 2 == 0, range(10)))
[0, 2, 4, 6, 8]
parejas = [(1, 'uno'), (2, 'dos'), (3, 'tres'), (4, 'cuatro')]
#pairs.sort(key=lambda pair: pair[1])
print(sorted(parejas, key=lambda p: p[0]))
print(sorted(parejas, key=lambda p: p[1]))
print(sorted(parejas, key=lambda p: len(p[1])))
[(1, 'uno'), (2, 'dos'), (3, 'tres'), (4, 'cuatro')]
[(4, 'cuatro'), (2, 'dos'), (3, 'tres'), (1, 'uno')]
[(1, 'uno'), (2, 'dos'), (3, 'tres'), (4, 'cuatro')]
2.4. Clases#
Se puede crear clases en Python utilizando class
El siguiente ejemplo muestra como se hace herencia de clases en Python
class Fruta:
def __init__(self, nombre, color):
self.nombre = nombre # Atributos públicos
self.color = color
self.__sabor = 'asd' # Este es un atributo privado
class Manzana(Fruta):
def __init__(self):
super().__init__("Manzana", "Rojo") # Llamamos al constructor de Fruta con super
mi_manzana = Manzana()
print(mi_manzana.color)
#mi_manzana.__atributo_privado
Rojo
2.5. Manejo y levantamiento de excepciones#
2.5.1. Bloque try/catch en Python#
def foo(x):
try:
return x/10
except TypeError:
print("Esta excepcion se captura")
else:
print("Estas excepciones se propagan")
finally:
print("Esto corre al final de cualquier camino (cleanup)")
foo('asd')
Esta excepcion se captura
Esto corre al final de cualquier camino (cleanup)
Es posible levantar excepciones utilizando raise y assert
Por ejemplo
raise TypeError("Algo no está bien aquí")
Retornaría una excepción TypeError: Algo no está bien aquí
Sea ahora la siguietne función:
def foo(x):
assert type(x) == int, "El argumento no es un entero"
return x + 1
Si ejecutáramos foo('a') se retornaría una excepción AssertionError: El argumento no es un entero
2.5.2. Debugging con ipdb#
A continuación se muestran dos formas para encontrar bugs con IPython usando el debugger ipdb
Nota
Necesitas tener instalado ipdb : conda install ipdb
1) Debugeo Paso-a-paso: Insertar breakpoints manualmente
def foo(x, y):
import ipdb; ipdb.set_trace(context=10) # Esto inserta un breakpoint en la función
z = x/2.
z += 2/y
return z
Si ejecutamos foo(1, 0) veremos algo como lo siguiente
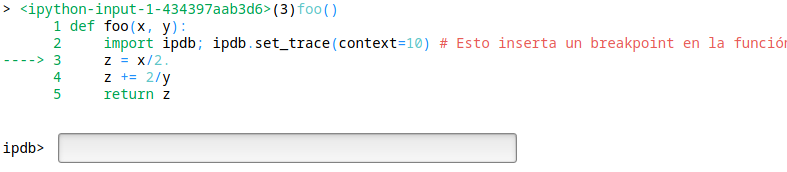
Comandos en ipdb:
a: Muestra los valores de los argumentos
l: Muestra la linea de código en que estamos posicionados
u/d: Sube y baja en el stack
q: Salir del modo debug
Debugeo Post-mortem: Entra a modo debug con ipdb cuando ocurre una excepción
# Esto activa el modo post-mortem
%pdb on
Automatic pdb calling has been turned ON
def foo(x, y):
z = x/2.
z += 2/y
return z
Si ejecutamos foo(1, 0) veremos algo como:
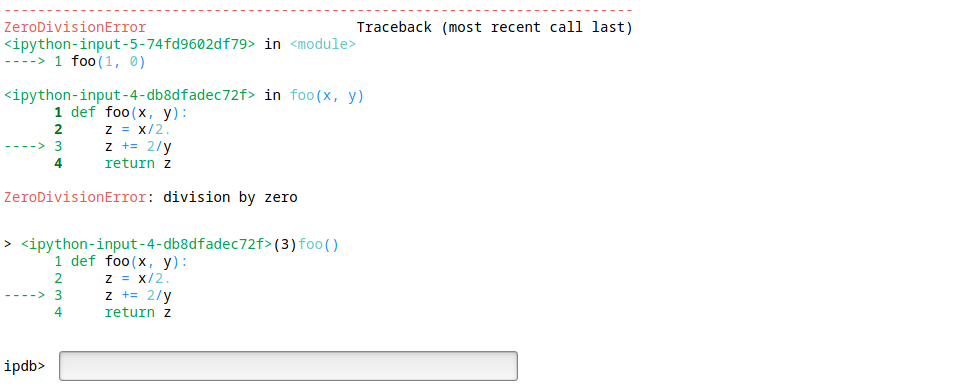
2.6. Interactuando con el sistema de archivos#
2.6.1. Manejadores de contexto#
Usando la palabra clave with no es necesario preocuparse de cerrar el archivo file.txt, luego de trabajar con él
!echo "hola mundo, soy un archivo" > file.txt
with open('file.txt') as f:
contents = f.read()
print(contents)
hola mundo, soy un archivo
2.6.2. Módulo pathlib#
Es un módulo estándar de Python para leer y manipular archivos y directorios
from pathlib import Path
p = Path('.')
print(sorted(p.glob('*.py')))
print([x for x in p.iterdir() if x.is_dir()])
print([x for x in p.iterdir() if x.is_file() and x])
p = Path('/usr/bin/python3')
print(p.parts)
[]
[PosixPath('.ipynb_checkpoints'), PosixPath('img')]
[PosixPath('git.ipynb'), PosixPath('env_management.ipynb'), PosixPath('python3.ipynb'), PosixPath('file.txt'), PosixPath('intro.ipynb')]
('/', 'usr', 'bin', 'python3')
2.7. Algunas buenas prácticas#
Usa nombres explicativos para las variables, funciones y clases
Prefiere variables keyword antes que posicionales
Manten las funciones y clases breves, si una función es muy grande es posible que en realidad sean dos funciones en una (Principio de “Single responsability”)
Prefiere los tipos nativos de Python, explora las librerías estándar de Python para evitar reimplementar algo que ya existe
Trata de seguir el PEP8
Python Enhancement Proposal (PEP) es una especificación técnica que busca mejorar el lenguaje Python
PEP 0 es el índice de todos los PEP existentes.
El PEP 8 es una guia de buenas prácticas para dar formato a nuestros códigos en Python
El objetivo de PEP 8 es mantener un estándar que facilite la lectura de código escrito en Python
Por último, recitemos el zen de Python:
import this
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!