2. Regresión Lineal#
2.1. Formulación matemática#
La regresión lineal es un modelo que mapea una o más variables continuas hacia una variable también continua. El modelo se define matemáticamente como:
Asumiendo que tenemos \(N\) ejemplos para entrenar, podemos plantear el sistema de ecuaciones matricialmente como
donde \(Y= \begin{pmatrix} y_1 \\ y_2 \\ \vdots \\y_N\end{pmatrix} \in \mathbb{R}^N\), \(X = \begin{pmatrix} 1 & x_{11} & x_{12}& \ldots& x_{1M} \\ \vdots & \vdots & \vdots& \ddots& \vdots \\ 1 & x_{N1} & x_{N2}& \ldots& x_{NM} \\ \end{pmatrix} \in \mathbb{R}^{N\times M}\) y \(\theta \in \mathbb{R}^M\)
Para medir la calidad del modelo usamos la suma de errores cuadrados, la cual en notación matricial es
Si derivamos e igualamos a cero la expresión anterior se obtiene
despejando la solución es
siempre \(X^T X\) no sea singular (no invertible).
Nota
El resultado anterior se conoce como la solución de mínimos cuadrados ordinarios (ordinary least squares o OLS).
2.2. Implementación en Scikit-Learn#
La solución de mínimos cuadrados está implementada en la librería scikit-learn como sklearn.linear_model.LinearRegression.
Sus principales argumentos son:
fit_intercept=True: Ajustar o no el parámetro \(\theta_0\)n_jobs: Número de nucleos de CPU para ajustar
Sus principales métodos son:
fit(X, y): Ajuste los parámetros según la solución de mínimos cuadrados.predict(X): Retorna la predicción para un conjunto de datosscore(X, y): Retorna el coeficiente de determinación
Nota
Xes un ndarray de dos dimensiones (matriz)yes un ndarray de una dimensión (vector)
Los principales atributos son:
intercept_: Corresponde a \(\theta_0\)coef_: Es un arreglo con \(\theta_j\) para \(j>0\)
Ejemplo
Consideremos los siguientes datos
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
np.random.seed(1234)
x = np.random.randn(30)
y = -0.5*x**4 + 2*x**3 -3 + np.random.randn(len(x))
Para ajustar el modelo a este dataset utilizamos
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(x.reshape(-1, 1), y)
print(f"Coeficiente de determinación: {model.score(x.reshape(-1, 1), y):0.4f}")
Coeficiente de determinación: 0.6603
Luego para realizar una predicción sobre nuevos datos:
x_test = np.linspace(x.min(), x.max(), 200)
y_test = model.predict(x_test.reshape(-1, 1))
A continuación se grafican los datos y la predicción del modelo (izquierda) junto a los residuos del modelo (derecha)
def plot_prediction(x, y, x_test, y_test, model):
fig, ax = plt.subplots(1, 2, figsize=(8, 4), sharey=True, tight_layout=True)
ax[0].scatter(x, y, s=50, label='Datos', alpha=0.5)
ax[0].plot(x_test, y_test, label='Modelo', lw=2, )
ax[0].legend()
ax[0].set_xlabel('x')
ax[0].set_ylabel('y')
ax[1].scatter(y, y - model.predict(x.reshape(-1, 1)), alpha=0.5)
ax[1].axhline(0, c='k', ls='--', alpha=0.5)
ax[1].set_xlabel('y')
ax[1].set_ylabel('residuos')
plot_prediction(x, y, x_test, y_test, model)
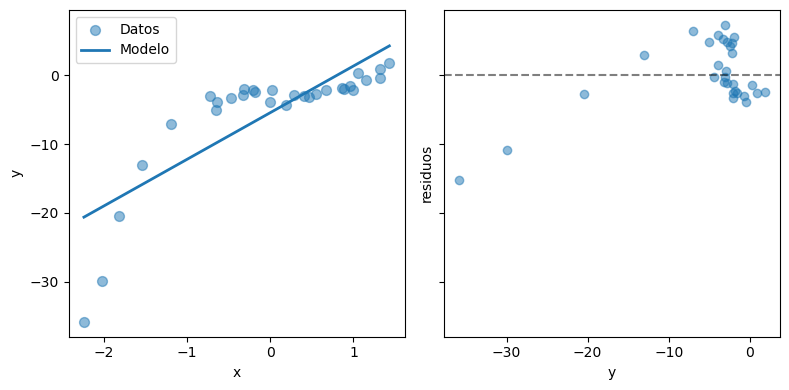
El gráfico de residuos es un gráfico de dispersión (scatter plot) de \(y\) versus \(y - f_\theta(x)\). Es bastante usado para analizar los errores de un modelo de regresión.
Importante
Un modelo adecuado debería tener sus residuos concentrados en torno a cero y libres de correlación.
En este caso, los residuos no cumplen ninguna de las condiciones anteriores.
También podemos medir la calidad del modelo utilizando el error medio cuadrático, que es la suma de errores cuadrados dividido por la cantidad de datos:
from sklearn.metrics import mean_squared_error
print(f"MSE: {mean_squared_error(y, model.predict(x.reshape(-1, 1))):0.4f}")
MSE: 24.1281
Mientras más cercano a cero sea el MSE, mejor es el ajuste del modelo.
2.3. Regresión polinomial con Scikit-Learn#
Podemos generalizar el regresor lineal aplicando transformaciones a los datos. Por ejemplo una regresión polinomial de grado \(M\) sería
y su solución sería
donde
Importante
El grado del polinomio es un hiperparámetro del modelo. Los hiperparámetros son valores que el usuario fija antes de ajustar.
En scikit learn podemos utilizar sklearn.preprocessing.PolynomialFeatures para realizar esta transformación. Por ejemplo un polinomio de grado dos se obtiene con:
from sklearn.preprocessing import PolynomialFeatures
featurizer = PolynomialFeatures(degree=2)
display(featurizer.fit_transform(np.array([[1.], [2.], [3.]])))
array([[1., 1., 1.],
[1., 2., 4.],
[1., 3., 9.]])
Podemos crear un regresor polinomial definiendo un Pipeline.
Nota
En scikit-learn, un pipeline es una cadena de objetos de scikit-learn. Si llamamos al método fit del pipeline, se llamará al método fit de cada elemento de la cadena en orden.
El siguiente pipeline combina PolynomialFeatures y LinearRegression:
from sklearn.pipeline import make_pipeline
model = make_pipeline(PolynomialFeatures(degree=3),
LinearRegression(fit_intercept=False))
model
Pipeline(steps=[('polynomialfeatures', PolynomialFeatures(degree=3)),
('linearregression', LinearRegression(fit_intercept=False))])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('polynomialfeatures', PolynomialFeatures(degree=3)),
('linearregression', LinearRegression(fit_intercept=False))])PolynomialFeatures(degree=3)
LinearRegression(fit_intercept=False)
model.fit(x.reshape(-1, 1), y)
print(f"MSE: {mean_squared_error(y, model.predict(x.reshape(-1, 1))):0.4f}")
y_test = model.predict(x_test.reshape(-1, 1))
MSE: 0.7179
plot_prediction(x, y, x_test, y_test, model)
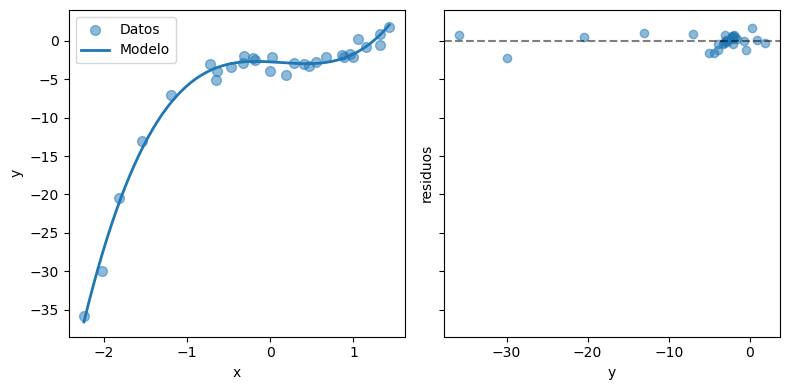
El MSE se ha reducido en comparación al caso anterior. Visualmente el modelo sigue mejor a los datos. Además los residuos están más concentrados en cero y tienen menos correlación.
¿Qué ocurre su usamos un polinomio de grado mayor?
Intentemos ajustar nuevamente pero con un polinomio de grado 15.
model = make_pipeline(PolynomialFeatures(degree=15),
LinearRegression())
model.fit(x.reshape(-1, 1), y)
print(f"MSE: {mean_squared_error(y, model.predict(x.reshape(-1, 1))):0.4f}")
y_test = model.predict(x_test.reshape(-1, 1))
MSE: 0.2526
plot_prediction(x, y, x_test, y_test, model)
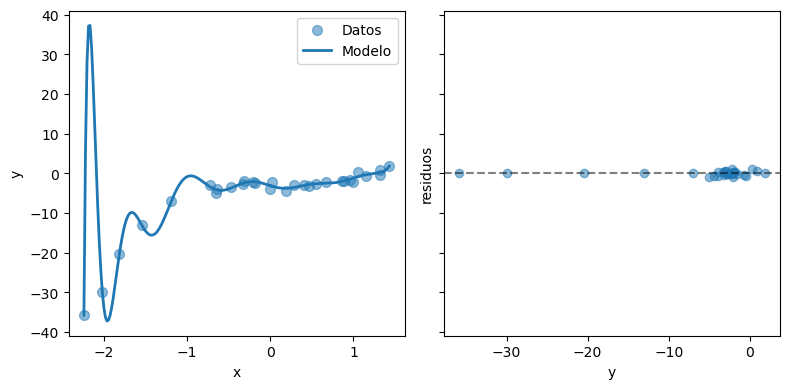
El MSE es aun más bajo, el modelo sigue perfectamente los datos y los residuos son casi cero.
¿Creé usted que este es un buen resultado?
Advertencia
Lo que estamos observando es un ejemplo de sobreajuste. Estudiaremos esto en detalle en la próxima lección.