10. Ingeniería de características#
Es muy común que los datos recolectados para resolver un problema de ML no estén originalmente en un formato o tipo compatible con el modelo de aprendizaje. Por ejemplo, la mayoría de los métodos que hemos visto en este curso requieren una entrada numérica.
Ejemplo Supongamos que tenemos un dataset de helados y uno de sus atributos es la marca de la empresa que produce el helado: Savory, Bresler, Panda.
Si queremos utilizar la marca como una entrada a un modelo predictivo podríamos codificar estas categorías como numéros enteros utilizando OrdinalEncoder
import numpy as np
from sklearn.preprocessing import OrdinalEncoder
marcas = np.array(['Savory', 'Bresler', 'Panda'])
enc = OrdinalEncoder()
enc.fit_transform(marcas.reshape(-1, 1))
array([[2.],
[0.],
[1.]])
enc.inverse_transform([[0]])
array([['Bresler']], dtype='<U7')
Error
Esta forma ingenua de codificar las categorías introduce una relación de orden ficticia que el modelo podría aprender.
Nota
Si el número de categorías no es grande, podemos codificarlas sin caer en una relación de orden utilizando one-hot encoding.
Podemos implementar esta codificación con OneHotEncoder
from sklearn.preprocessing import OneHotEncoder
enc = OneHotEncoder(sparse_output=False)
enc.fit_transform(marcas.reshape(-1, 1))
array([[0., 0., 1.],
[1., 0., 0.],
[0., 1., 0.]])
enc.inverse_transform([[0, 0, 1]])
array([['Savory']], dtype='<U7')
donde todas las categorías están a una misma distancia de las demás. Esta secuencia de tres números puede ingresar como entrada al modelo.
Nota
En problemas con muchas categorías estaríamos creando vectores de gran tamaño. Un solución típica es agrupar las categorías minoritarias. Esto se puede hacer con OneHotEncoder utilizando el argumento max_categories.
Más en general, podemos definir:
- Característica (feature)
Se refiere a una cantidad obtenida de codificar o transformar los datos (crudos) que puede usarse como entrada de un modelo.
- Ingeniería de características (feature engineering)
Se refiere a los criterios y procesos para diseñar y obtener características a partir de datos crudos
Una característica “ideal” debería cumplir con lo siguiente:
Alto poder predictor: La característica debe estar altamente relacionada con la variable a predecir (etiqueta).
Baja correlación con otras características: La característica no debe proveer información que esté en otras características.
Alta confianza: La característica debe calcularse a partir de datos que son confiables y representativos del problema.
Rápida de calcular: El cálculo de la característica no debería introducir un overhead computacional que vuelva infactible resolver el problema.
Importante
La ingeniería de características es un proceso creativo que requiere que nos acerquemos considerablemente al problema que se quiere resolver. En ciertos problemas será necesario colaborar con un experto del dominio específico.
Discusión: Un médico quiere predecir cancer a partir de una biopsia. El médico resuelve esta tarea observando el tamaño de ciertas células que se caracterisan por su color distintivo ¿Qué características diseñar para este problema?
Si en un problema particular los datos corresponden a los siguientes tipos, podemos considerar las siguientes representaciones para obtener características:
Textos: Modelos de tópicos (LDA), Bag of Words, Word2Vec
Audio: Espectrogramas, Wavelets
Imágenes: Filtros de extracción de contornos, Gradientes de color, matching de geométrias,
Series de tiempo: Modelos autoregresivos
Ejemplo de características para un dominio particular: astronomía
10.1. Selección de características#
Los métodos de selección de características buscan encontrar el subconjunto de características más relevantes para resolver el problema (clasificación o regresión). En el caso más general estos métodos suelen distinguir entre:
- Características relevante
Es una características que tiene alto poder predictivo, es decir una relación (lineal o no lineal) fuerte con la variable a predecir (etiqueta).
- Características complementarias o sinérgicas
Son tuplas de características que por si sola tienen bajo poder predictivo, pero estándo juntas tienen alto poder predictivo.
- Característica redundante
Es una característica que si se elimina no afecta el desempeño pues su relación con la etiqueta ya está bien representada por otras variables.
- Característica irrelevante
Es una característica con relación débil o nula con la etiqueta.
Importante
Un buen método de selección debería preservar las características relevantes/complementarias y descartar las irrevelante/redundantes.
Nota
Eliminar características de poco poder predictivo puede mejorar el rendimiento del clasificador, especialmente si tenemos muchas características (la maldición de la dimensionalidad).
El módulo feature_selection de Scikit-Learn ofrece algunas alternativas para hacer selección de características. Revisemos primero SelectKBest. Este objeto espera una función que mida la relevencia de las características y en base a eso retorna las K características más relevantes.
Una métrica muy utilizada para medir relevancia es la Información Mutua, que también está implementada en scikit learn como mutual_info_classif y mutual_info_regression.
Nota
La Información Mutua (IM) mide la cantidad de información compartida entre una característica y la etiqueta. A diferencia de la correlación, la IM es sensible a relaciones no lineales.
Utilicemos como ejemplo un dataset de clasificación sintético de dos clases con seis características:
Las primeras dos características son relevantes (informativas).
Las segundas dos son redundantes con las dos primeras.
Las dos restantes son irrelevantes.
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=300, n_classes=2, n_features=6,
n_informative=2, n_redundant=2, n_clusters_per_class=1,
shuffle=False, random_state=0)
La información mutua es:
from sklearn.feature_selection import mutual_info_classif, SelectKBest
mutual_info_classif(X, y)
array([0.066961 , 0.40360162, 0.0787783 , 0.46676115, 0.0506025 ,
0. ])
La IM de las variables irrelevantes es practicamente nula
La IM de las variables informativas y relevantes es similar
Si utilizamos SelectKBest con \(K=3\)
%%time
selector = SelectKBest(score_func=mutual_info_classif, k=3)
X_reduced = selector.fit_transform(X, y)
X_reduced.shape, selector.get_feature_names_out()
CPU times: user 28.4 ms, sys: 660 µs, total: 29.1 ms
Wall time: 27.7 ms
((300, 3), array(['x1', 'x2', 'x3'], dtype=object))
Nota
La ventaja de este método para hacer selección de características es que no depende de un modelo de clasificación en particular. Otra ventaja es que es muy eficiente computacionalmente.
Advertencia
La desventaja de este método es que, al medir la relevancia de las características una por una, no es sensible a relaciones de redundancia y complementariedad.
El problema anterior se puede aliviar utilizando un método de eliminación hacia-atras (backward). Scikit-learn tiene dos objetos para lograr este propósito:
RFE(Recursive feature elimination)
Ambos métodos requieren de un estimador (regresor o clasificador) y se utiliza el accuracy en validación cruzada para hacer la selección.
En particular SequentialFeatureSelector
Mide el accuracy utilizando todas las características menos una, para todas las características
Elimina la característica que produje la menor disminución en accuracy
El procedimiento se repite hasta que cumplir con un número esperado de característas especificado por el argumento
n_features_to_select
Nota
Este tipo de eliminación greedy descartará características redundates y no perderá características que son complementarias, pero tiene un gran costo en comparación a lo que vimos antes.
Por ejemplo, si pedimos tres características:
%%time
from sklearn.tree import DecisionTreeClassifier
from sklearn.feature_selection import SequentialFeatureSelector
model = DecisionTreeClassifier(random_state=0)
selector = SequentialFeatureSelector(model, direction='backward', cv=3,
n_features_to_select=3)
selector.fit(X, y)
selector.get_feature_names_out()
CPU times: user 149 ms, sys: 5.98 ms, total: 155 ms
Wall time: 154 ms
array(['x0', 'x3', 'x5'], dtype=object)
El método no entrega características redudantes entre si.
Advertencia
Los resultados dependen del estimador. Usar un estimador distinto puede cambiar considerablemente el resultado.
10.2. Escalamiento y normalización de características#
Existen dos razones importantes por las cuales es interesante escalar las características antes de entrenar un modelo:
Evitar que una variable domine a las otras sólo por tener valores más grandes
Evitar inestabilidad numérica en el modelo o en el proceso de optimización del mismo]
El módulo preprocessing de Scikit Learn proporciona clases y funciones para realizar distintos tipos de escalamiento, entre ellos:
StandardScaler(with_mean=True, with_std=True): Equivalente a restar la media y dividir por la desviación estándarMinMaxScaler(): Reescala la variable tal que su valor mínimo sea 0 y su valor máximo sea 1MaxAbsScaler(): Rescala la variable tal que su valor máximo sea 1 (divide por el máximo absoluto)RobustScaler(): Similar aStandardScalerpero utiliza estadísticos robustos ante los valores fuera de rango (outliers)
Los principales métodos de estas clases son:
fit(X): Calcula los estadísticos de la transformación de escalamiento paraXtransform(X)Aplica la transformación aXfit_transform(X): Equivalente a aplicar los dos pasos anteriores al mismo tiempoinverse_transform(X): Deshace la transformación
from sklearn.preprocessing import MinMaxScaler
data = np.random.randn(5, 2)
scaler = MinMaxScaler()
scaler.fit_transform(data)
array([[0.15596611, 0.54159956],
[0. , 0. ],
[0.71403426, 1. ],
[1. , 0.68908574],
[0.48256434, 0.77515863]])
Importante
Si entrenas sobre características reescaladas debes guardar los valores de los estadísticos para poder normalizar/reescalar ejemplos futuros
10.3. Reducción de dimensionalidad#
Los métodos de reducción de dimensionalidad transforman un conjunto de características (numéricas) en un nuevo conjunto con un número menor de variables. Las nuevas características suelen involucrar transformaciones y combinaciones de las características originales.
Existen métodos supervisados y no supervisados para reducir dimensionalidad. En este último caso no se utiliza información de la etiqueta, y se busca minimizar otro tipo de objetivo. Un ejemplo clásico y ampliamente utilizado es Análisis de Componentes Principales (Principal Component Analysis, PCA).
Como muestra la siguiente figura, PCA aplica una transformación sobre las características originales (izquierda), creando nuevas características que son combinaciones lineales de las originales (derecha).
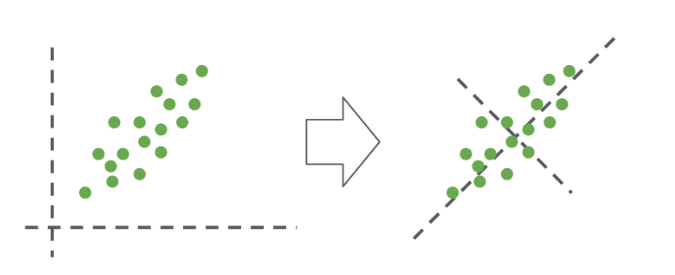
El objetivo de PCA es maximizar la varianza de las características proyectadas en el nuevo espacio.
Nota
PCA produce una cantidad de características equivalente a las que se tenían originalmente.
Importante
La reducción de dimensionalidad en PCA es manual, es decir el usuario debe decidir cuantas características preservar. Un criterio muy usado es seleccionar la cantidad de características en base a la varianza acumulada que representan.
El módulo decomposition de scikit-learn tiene clases y objetos para hacer reducción de dimensionalidad, entre ellos PCA.
El argumento principal de PCA es n_components, el cual puede ser un entero o un flotante en el rango [0, 1]:
Si es un entero \(K\) el método se quedará con las \(K\) variables de mayor varianza
Si es un flotante \(p\) el método se quedará con tantas variables como sea necesario con tal de tener un \(100p\%\) de la varianza
Veamos un ejemplo con el famoso dataset Iris.
from sklearn.datasets import load_iris
X, y = load_iris(return_X_y=True)
X.shape
(150, 4)
from sklearn.decomposition import PCA
dim_reducer = PCA(n_components=0.95)
X_reduced = dim_reducer.fit_transform(X)
X_reduced.shape
(150, 2)
De acuerdo a los resultados, dos componentes principales son suficientes para preservar un 95% de la varianza
Los datos en el espacio proyectado son:
%matplotlib inline
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(6, 4), tight_layout=True)
for y_ in np.unique(y):
mask = y == y_
ax.scatter(X_reduced[mask, 0], X_reduced[mask, 1])
ax.set_xlabel('Componente principal 1')
ax.set_ylabel('Componente principal 2');
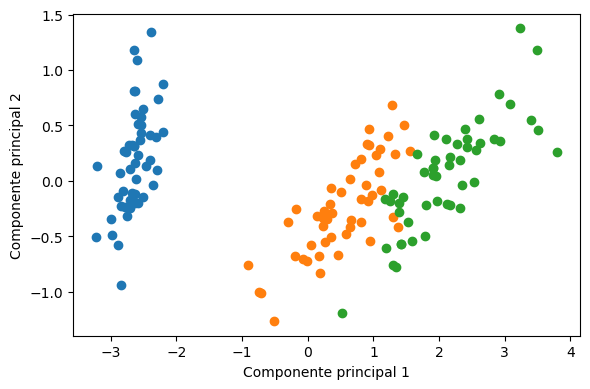
Estos nuevas características parecen suficiente para separar las tres clases.
Advertencia
PCA no utiliza la información de clases para hacer la proyección. No siempre maximizar varianza resultará en mayor separabilidad de clases.
Ver también
PCA recibe su nombre debido a que las nuevas características y su varianza están relacionadas a los vectores y valores propios de la matriz de correlación de las características originales. Puedes profundizar sobre este tema leyendo esta presentación.