24. DQN a partir de píxeles#
24.1. Arcade Learning Environment#
La librería gymnasium se conecta con el Arcade Learning Environment (ALE) el cual tiene una colección de juegos de ATARI 2600 listos para utilizarle como benchmark de aprendizaje por refuerzo. La mayoría tiene una versión normal y una versión RAM:
En la versión normal las observaciones son imágenes de 260x120x3
En la versión RAM las observaciones son 128 bits que corresponden a la memoria de la consola
En este ejemplo nos concentraremos en la versión normal. Veamos por ejemplo el clásico juego Breakout
import gymnasium as gym
#env_name = "PongNoFrameskip-v4"
env_name ="BreakoutNoFrameskip-v4"
#env_name = "SpaceInvadersNoFrameskip-v4"
env = gym.make(env_name, render_mode="rgb_array")
state, _ = env.reset()
display("Las acciones de este ambiente:", env.unwrapped.get_action_meanings())
display("La dimensión del estado:", state.shape)
'Las acciones de este ambiente:'
['NOOP', 'FIRE', 'RIGHT', 'LEFT']
'La dimensión del estado:'
(210, 160, 3)
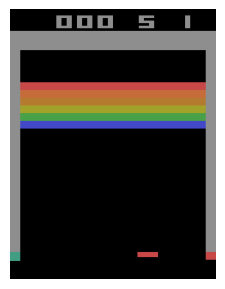
El estado es una imagen de 210 x 160 x 3 pixeles:
%matplotlib inline
from matplotlib import pyplot as plt
fig, ax = plt.subplots(figsize=(5, 3), tight_layout=True)
ax.imshow(state)
ax.axis('off');
24.2. Entrenamiento con stable_baselines3#
Para facilitar el entrenamiento se recomienda hacer un preprocesamiento como el que sigue:
Reescalar la imagen a un menor tamaño
Combinar los canales y generar una imagen de escala de grises
Crear un stack de cuatro frames como representación del estado
Convertir los pixeles a float y normalizar al rango [0, 1]
Adicionalmente es muy útil entrenar con más de un ambiente al mismo tiempo en paralelo.
Para esto usaremos los wrappers vectoriales de stable_baselines3:
import numpy as np
import torch
from stable_baselines3.common.env_util import make_atari_env
from stable_baselines3.common.vec_env import VecFrameStack
env = VecFrameStack(make_atari_env(env_name, n_envs=4), n_stack=4)
env.reset()
state, _, _, _ = env.step([2, 2, 2, 2])
print(f"Tamaño del tensor transformado: {state.shape, state.dtype}")
fig, ax = plt.subplots(1, 4, figsize=(8, 2), tight_layout=True)
for k in range(4):
ax[k].matshow(state[k, :, :, 2], cmap=plt.cm.Greys_r);
ax[k].axis('off')
Tamaño del tensor transformado: ((4, 84, 84, 4), dtype('uint8'))

Veamos un agente aleatorio desempeñándose en este ambiente:
import imageio
import IPython
images = []
obs = env.reset()
for k in range(100):
action = env.action_space.sample()
obs, rewards, end, info = env.step([action]*4)
img = env.render("rgb_array")
images.append(img)
!rm random.gif
imageio.mimsave("random.gif", [np.array(img) for img in images], format='GIF', duration=1)
IPython.display.Image("random.gif")
/home/phuijse/.conda/envs/RL/lib/python3.9/site-packages/gymnasium/utils/passive_env_checker.py:364: UserWarning: WARN: No render fps was declared in the environment (env.metadata['render_fps'] is None or not defined), rendering may occur at inconsistent fps.
logger.warn(
Para entrenar el agente utilizaremos una red convolucional CnnPolicy. Utilizaremos un buffer de tamaño 100.000 y durante las primeros 100.000 pasos no entrenamos, sólo llenamos el buffer.
Advertencia
Para llegar a un buen resultado en los ambientes de Atari con DQN se necesitan al menos 1.000.000 de pasos con la configuración que se muestra a continuación. Se recomienda utilizar una GPU para entrenar. En la práctica también es recomendable utilizar algoritmos más eficientes como A3C.
%%time
import torch
from stable_baselines3 import DQN
np.random.seed(1234)
torch.manual_seed(1234)
env.reset()
model = DQN("CnnPolicy", env, verbose=1, tensorboard_log="/tmp/tensorboard/dqn_atari/",
gamma=0.99, learning_rate=1e-4, batch_size=32, buffer_size=100_000,
target_update_interval=1_000, train_freq=4, gradient_steps=1,
learning_starts=100_000,
exploration_fraction=0.1, exploration_final_eps=0.01,
)
model.learn(total_timesteps=10_000_000)
Show code cell output
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
Cell In[8], line 15
7 env.reset()
8 model = DQN("CnnPolicy", env, verbose=1, tensorboard_log="/tmp/tensorboard/dqn_atari/",
9 gamma=0.99, learning_rate=1e-4, batch_size=32, buffer_size=100_000,
10 target_update_interval=1_000, train_freq=4, gradient_steps=1,
11 learning_starts=100_000,
12 exploration_fraction=0.1, exploration_final_eps=0.01,
13 )
---> 15 model.learn(total_timesteps=10_000_000)
File ~/.conda/envs/RL/lib/python3.9/site-packages/stable_baselines3/dqn/dqn.py:267, in DQN.learn(self, total_timesteps, callback, log_interval, tb_log_name, reset_num_timesteps, progress_bar)
258 def learn(
259 self: SelfDQN,
260 total_timesteps: int,
(...)
265 progress_bar: bool = False,
266 ) -> SelfDQN:
--> 267 return super().learn(
268 total_timesteps=total_timesteps,
269 callback=callback,
270 log_interval=log_interval,
271 tb_log_name=tb_log_name,
272 reset_num_timesteps=reset_num_timesteps,
273 progress_bar=progress_bar,
274 )
File ~/.conda/envs/RL/lib/python3.9/site-packages/stable_baselines3/common/off_policy_algorithm.py:312, in OffPolicyAlgorithm.learn(self, total_timesteps, callback, log_interval, tb_log_name, reset_num_timesteps, progress_bar)
309 callback.on_training_start(locals(), globals())
311 while self.num_timesteps < total_timesteps:
--> 312 rollout = self.collect_rollouts(
313 self.env,
314 train_freq=self.train_freq,
315 action_noise=self.action_noise,
316 callback=callback,
317 learning_starts=self.learning_starts,
318 replay_buffer=self.replay_buffer,
319 log_interval=log_interval,
320 )
322 if rollout.continue_training is False:
323 break
File ~/.conda/envs/RL/lib/python3.9/site-packages/stable_baselines3/common/off_policy_algorithm.py:544, in OffPolicyAlgorithm.collect_rollouts(self, env, callback, train_freq, replay_buffer, action_noise, learning_starts, log_interval)
541 actions, buffer_actions = self._sample_action(learning_starts, action_noise, env.num_envs)
543 # Rescale and perform action
--> 544 new_obs, rewards, dones, infos = env.step(actions)
546 self.num_timesteps += env.num_envs
547 num_collected_steps += 1
File ~/.conda/envs/RL/lib/python3.9/site-packages/stable_baselines3/common/vec_env/base_vec_env.py:197, in VecEnv.step(self, actions)
190 """
191 Step the environments with the given action
192
193 :param actions: the action
194 :return: observation, reward, done, information
195 """
196 self.step_async(actions)
--> 197 return self.step_wait()
File ~/.conda/envs/RL/lib/python3.9/site-packages/stable_baselines3/common/vec_env/vec_transpose.py:95, in VecTransposeImage.step_wait(self)
94 def step_wait(self) -> VecEnvStepReturn:
---> 95 observations, rewards, dones, infos = self.venv.step_wait()
97 # Transpose the terminal observations
98 for idx, done in enumerate(dones):
File ~/.conda/envs/RL/lib/python3.9/site-packages/stable_baselines3/common/vec_env/vec_frame_stack.py:33, in VecFrameStack.step_wait(self)
30 def step_wait(
31 self,
32 ) -> Tuple[Union[np.ndarray, Dict[str, np.ndarray]], np.ndarray, np.ndarray, List[Dict[str, Any]],]:
---> 33 observations, rewards, dones, infos = self.venv.step_wait()
34 observations, infos = self.stacked_obs.update(observations, dones, infos) # type: ignore[arg-type]
35 return observations, rewards, dones, infos
File ~/.conda/envs/RL/lib/python3.9/site-packages/stable_baselines3/common/vec_env/dummy_vec_env.py:58, in DummyVecEnv.step_wait(self)
55 def step_wait(self) -> VecEnvStepReturn:
56 # Avoid circular imports
57 for env_idx in range(self.num_envs):
---> 58 obs, self.buf_rews[env_idx], terminated, truncated, self.buf_infos[env_idx] = self.envs[env_idx].step(
59 self.actions[env_idx]
60 )
61 # convert to SB3 VecEnv api
62 self.buf_dones[env_idx] = terminated or truncated
File ~/.conda/envs/RL/lib/python3.9/site-packages/gymnasium/core.py:408, in Wrapper.step(self, action)
404 def step(
405 self, action: WrapperActType
406 ) -> tuple[WrapperObsType, SupportsFloat, bool, bool, dict[str, Any]]:
407 """Uses the :meth:`step` of the :attr:`env` that can be overwritten to change the returned data."""
--> 408 return self.env.step(action)
File ~/.conda/envs/RL/lib/python3.9/site-packages/gymnasium/core.py:502, in RewardWrapper.step(self, action)
498 def step(
499 self, action: ActType
500 ) -> tuple[ObsType, SupportsFloat, bool, bool, dict[str, Any]]:
501 """Modifies the :attr:`env` :meth:`step` reward using :meth:`self.reward`."""
--> 502 observation, reward, terminated, truncated, info = self.env.step(action)
503 return observation, self.reward(reward), terminated, truncated, info
File ~/.conda/envs/RL/lib/python3.9/site-packages/gymnasium/core.py:469, in ObservationWrapper.step(self, action)
465 def step(
466 self, action: ActType
467 ) -> tuple[WrapperObsType, SupportsFloat, bool, bool, dict[str, Any]]:
468 """Modifies the :attr:`env` after calling :meth:`step` using :meth:`self.observation` on the returned observations."""
--> 469 observation, reward, terminated, truncated, info = self.env.step(action)
470 return self.observation(observation), reward, terminated, truncated, info
File ~/.conda/envs/RL/lib/python3.9/site-packages/gymnasium/core.py:408, in Wrapper.step(self, action)
404 def step(
405 self, action: WrapperActType
406 ) -> tuple[WrapperObsType, SupportsFloat, bool, bool, dict[str, Any]]:
407 """Uses the :meth:`step` of the :attr:`env` that can be overwritten to change the returned data."""
--> 408 return self.env.step(action)
File ~/.conda/envs/RL/lib/python3.9/site-packages/stable_baselines3/common/atari_wrappers.py:112, in EpisodicLifeEnv.step(self, action)
111 def step(self, action: int) -> AtariStepReturn:
--> 112 obs, reward, terminated, truncated, info = self.env.step(action)
113 self.was_real_done = terminated or truncated
114 # check current lives, make loss of life terminal,
115 # then update lives to handle bonus lives
File ~/.conda/envs/RL/lib/python3.9/site-packages/stable_baselines3/common/atari_wrappers.py:178, in MaxAndSkipEnv.step(self, action)
176 terminated = truncated = False
177 for i in range(self._skip):
--> 178 obs, reward, terminated, truncated, info = self.env.step(action)
179 done = terminated or truncated
180 if i == self._skip - 2:
File ~/.conda/envs/RL/lib/python3.9/site-packages/gymnasium/core.py:408, in Wrapper.step(self, action)
404 def step(
405 self, action: WrapperActType
406 ) -> tuple[WrapperObsType, SupportsFloat, bool, bool, dict[str, Any]]:
407 """Uses the :meth:`step` of the :attr:`env` that can be overwritten to change the returned data."""
--> 408 return self.env.step(action)
File ~/.conda/envs/RL/lib/python3.9/site-packages/stable_baselines3/common/monitor.py:94, in Monitor.step(self, action)
92 if self.needs_reset:
93 raise RuntimeError("Tried to step environment that needs reset")
---> 94 observation, reward, terminated, truncated, info = self.env.step(action)
95 self.rewards.append(float(reward))
96 if terminated or truncated:
File ~/.conda/envs/RL/lib/python3.9/site-packages/gymnasium/wrappers/order_enforcing.py:56, in OrderEnforcing.step(self, action)
54 if not self._has_reset:
55 raise ResetNeeded("Cannot call env.step() before calling env.reset()")
---> 56 return self.env.step(action)
File ~/.conda/envs/RL/lib/python3.9/site-packages/gymnasium/wrappers/env_checker.py:49, in PassiveEnvChecker.step(self, action)
47 return env_step_passive_checker(self.env, action)
48 else:
---> 49 return self.env.step(action)
File ~/.conda/envs/RL/lib/python3.9/site-packages/shimmy/atari_env.py:294, in AtariEnv.step(self, action_ind)
292 reward = 0.0
293 for _ in range(frameskip):
--> 294 reward += self.ale.act(action)
295 is_terminal = self.ale.game_over(with_truncation=False)
296 is_truncated = self.ale.game_truncated()
KeyboardInterrupt:
CPU times: user 8.3 s, sys: 135 ms, total: 8.44 s
Wall time: 7.68 s
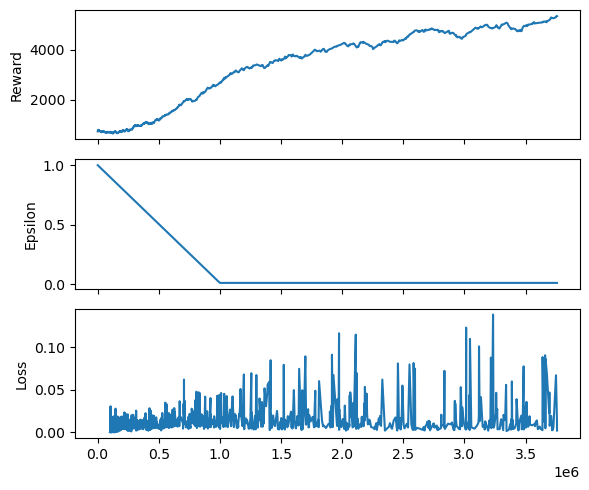
Las métricas del entrenamiento en este caso:
import pandas as pd
reward = pd.read_csv("metrics/rewards.csv")[['Step', 'Value']].values
epsilon = pd.read_csv("metrics/epsilon.csv")[['Step', 'Value']].values
loss = pd.read_csv("metrics/loss.csv")[['Step', 'Value']].values
fig, ax = plt.subplots(3, 1, figsize=(6, 5), tight_layout=True, sharex=True)
ax[0].plot(rewards[:, 0], rewards[:, 1])
ax[0].set_ylabel('Reward')
ax[1].plot(epsilon[:, 0], epsilon[:, 1])
ax[1].set_ylabel('Epsilon')
ax[2].plot(loss[:, 0], loss[:, 1])
ax[2].set_ylabel('Loss');
ax[2].set_xlabel('Epoca');
El mejor modelo se puede guardar en respaldar en disco con:
model.save("dqn_breakout")
El modelo guardado se puede cargar desde disco para evaluarse o también seguir entrenándose volviendo a ejecutar learn
import numpy as np
import imageio
import IPython
from stable_baselines3.common.env_util import make_atari_env
from stable_baselines3.common.vec_env import VecFrameStack
from stable_baselines3 import DQN
env = VecFrameStack(make_atari_env(env_name, n_envs=4), n_stack=4)
loaded_model = DQN.load("dqn_breakout")
images = []
obs = env.reset()
for k in range(100):
action, _state = loaded_model.predict(obs)
obs, rewards, end, info = env.step(action)
img = env.render("rgb_array")
images.append(img)
!rm trained.gif
imageio.mimsave("trained.gif", [np.array(img) for img in images], format='GIF', duration=1)
IPython.display.Image("trained.gif")