Approximate Inference
Contents
Approximate Inference¶
For many interesting models (e.g. neural networks) the evidence
is intractable, i.e either the integral has no closed-form or the dimensionality is so big that numerical integration is not feasible
If the evidence is intractable then the posterior is also intractable
In these cases we resort to approximations
Stochastic approximation: For example Markov Chain Monte Carlo (MCMC). MCMC is computationally demanding (for complex models) but produces asymptotically exact samples from the intractable distribution
Deterministic approximation: For example Variational Inference (VI). VI is more efficient than MCMC, but it is not asymptotically exact. Instead of samples we get a direct approximation of the intractable distribution
The main topic of this lecture is deterministic approximations
The Laplace Approximation¶
In Bayesian statistics, the Laplace approximation refers to the application of Laplace’s method to approximate an intractable integral (evidence) using a Gaussian distribution
In particular, Laplace’s method is a technique to solve integrals of the form
by defining the auxiliary function as
then \(f(x)\) is equivalent to the evidence.
The “approximation” consists of performing a second order Taylor expansion of \(g(\theta)\) around \(\theta= \hat \theta_{\text{map}}\), i.e. the MAP solution. The result of this is
where
is the negative Hessian evaluated at \(\hat \theta_{\text{map}}\)
Note
By definition the first derivative of \(g(\theta)\) evaluated at \(\hat \theta_{\text{map}}\) is zero
If we plug the Gaussian approximation back into the evidence we can now solve the integral as
where \(K\) is the dimensionality of \(\theta\). With this the posterior is
Important
Laplace’s method approximates the posterior by a Multivariate Gaussian centered on the MAP.
Warning
As the following figure shows, Laplace’s method might not be the “best” gaussian fit to our distribution
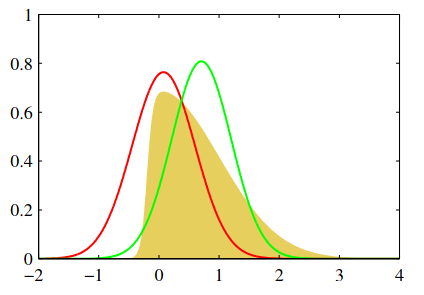
A non-gaussian distribution is shown in yellow. The red line corresponds to a gaussian centered on the mode (Laplace approximation), while the green line corresponds to a gaussian with minimum reverse KL divergence
Requirement of the Laplace approximation
For Laplace’s approximation the MAP solution and the negative Hessian evaluated at the MAP solution are needed
In the first place \(g(\theta)\) has to be continuous and differentiable on \(\theta\), and the negative Hessian has to be positive definite
A closer look to the evidence in Laplace approximation
Using Laplace approximation the log evidence can be decomposed as
i.e. the log evidence is approximated by the best likelihood fit plus the Occam’s factor
The Occam’s factor depends on the
log pdf of \(\theta\): Prior
number of parameters \(K\): Complexity
second derivative around the MAP: Model uncertainty
Relationship between the evidence in Laplace approximation and the BIC
In the regime of very large number of samples (\(N\)) it can be shown that Laplace’s approximations is dominated by
where \(\theta_{\text{mle}}\) is the maximum likelihood solution.
The expression above is equivalent to the negative of the Bayesian Information Criterion (BIC)
See also
Chapters 27 and 28 of D. Mackay’s book
Section 28.2 of D. Barber’s book
Variational Inference¶
In this section we review a more general method for deterministic approximation. Remember that we are interested in the (intractable) posterior
Variational Inference (VI) is a family of methods in which a simpler (tractable) posterior distribution is proposed to “replace” \(p(\theta|\mathcal{D})\). This simpler posterior is denoted as \(q_\nu(\theta)\) which represents a family of distributions parameterized by \(\nu\)
Optimization problem: The objective is to find \(\nu\) that makes \(q\) most similar to \(p\)
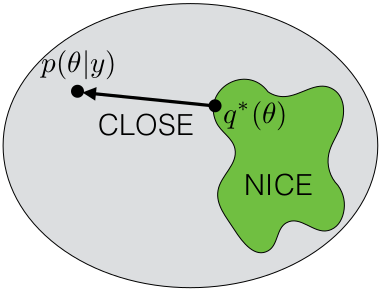
We can formalize this as a KL divergence minimization problem
but this expression depends on the intractable posterior. To continue we use Bayes Theorem to move the evidence out from the integral
As \(p(\mathcal{D})\) does not depend on \(\nu\) we can focus on the right hand term. The optimization problem is typically written as
where \( \mathcal{L}(\nu)\) is called the Evidence Lower BOund (ELBO).
The name comes from the fact that
which is a result of the non-negativity of the KL divergence.
Ideally we choose a “simple-enough” parametric family \(q\) so that the ELBO is tractable
Note
The ELBO can only be tight if \(p\) is within the family of \(q\)
See also
Calculus of variations: Derivatives of functionals (function of functions)
More attention on the ELBO¶
The ELBO can also be decomposed as
From which we can recognize that maximizing the ELBO is equivalent to:
Maximizing the log likelihood for parameters sampled from the approximate posterior: Generative model produces realistic data samples
Minimizing the KL divergence between the approximate posterior and prior: Regularization for the approximate posterior
Another way to “obtain” the ELBO
We can get the ELBO using Jensen’s inequality on the log evidence
A simple posterior: Fully-factorized posterior¶
A broadly-used idea to make posteriors tractable is to assume that there is no correlation between factors
this is known as the Mean-field VI
Replacing this factorized posterior on the ELBO
Asumming that we keep all \(\theta\) except \(\theta_i\) fixed, we can update \(\theta_i\) iteratively using
Note
(In this case) Maximizing the ELBO is equivalent to minimizing the KL between \(q_{\nu_i}(\theta_i)\) and \(\mathbb{E}_{\prod q_{i\neq j}} \left[ p(\mathcal{D}, \theta) \right ]\)
The optimal \(q\) in this case is given by
See also
Chapters 33 of D. Mackay’s book
Section 28.4 of D. Barber’s book
David Blei, “Variational Inference: A review for statisticians”, “Foundations and innovations”
Tamara Broderick, “Variational Bayes and beyond: Bayesian inference for big data”